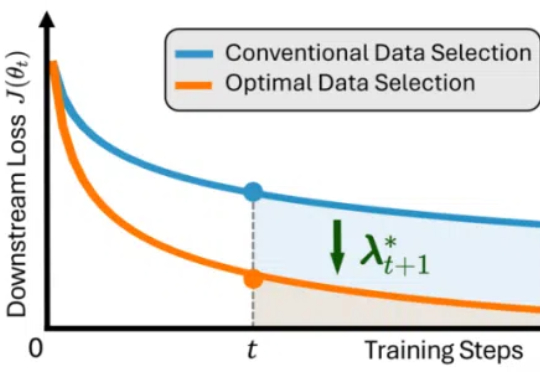
ICLR 2025 Oral | 训练LLM,不只是多喂数据,PDS框架给出最优控制理论选择
ICLR 2025 Oral | 训练LLM,不只是多喂数据,PDS框架给出最优控制理论选择近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。
来自主题: AI技术研报
9506 点击 2025-04-26 14:36
 搜索
搜索
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。

算力砍半,视觉生成任务依然SOTA!

一年一度ICLR 2025杰出论文开奖!普林斯顿、UBC、中科大NUS等团队的论文拔得头筹,还有Meta团队「分割一切」SAM 2摘得荣誉提名。
顶会论文评审,AI立大功!ICLR 2025首次大规模引入AI参与审稿,最终有12222条建议被审稿人采纳,89%情况下提升了评审质量。详细30页报告,揭秘AI在顶会审稿的惊人潜力。
ICLR 2025时间检验奖重磅揭晓!Yoshua Bengio与华人科学家Jimmy Ba分别领衔的两篇十年前论文摘得冠军与亚军。一个是Adam优化器,另一个注意力机制,彻底重塑深度学习的未来。

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

大家还记得那个 ICLR 2025 首次满分接收、彻底颠覆静态图像光照编辑的工作 IC-Light 吗?
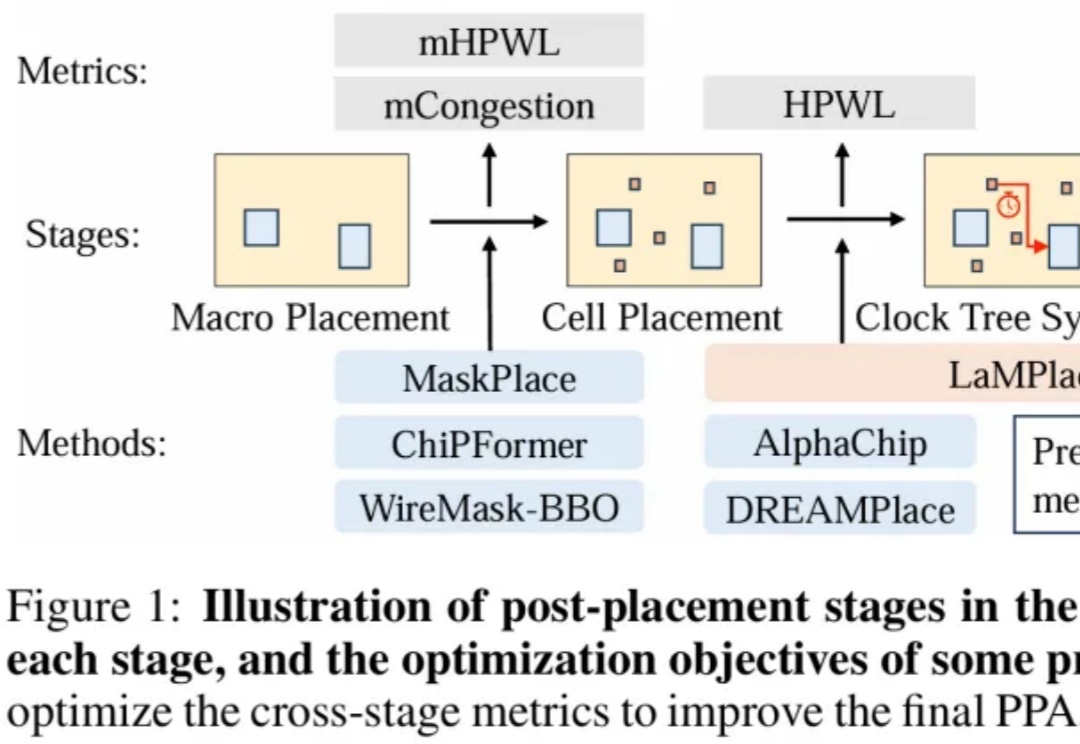
用AI指导芯片设计,中科大王杰教授团队、华为诺亚实验室、天津大学提出全新芯片宏单元布局优化方法LaMPlace!
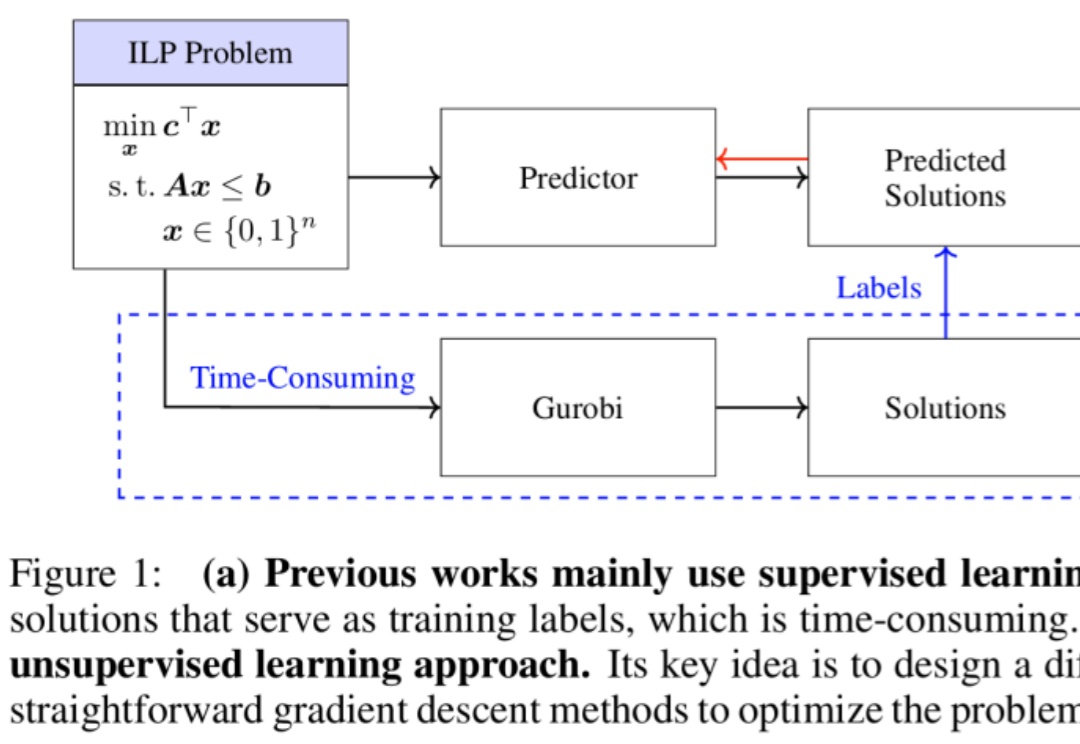
无监督学习训练整数规划求解器的新范式来了。

低秩适配器(LoRA)能够在有监督微调中以约 5% 的可训练参数实现全参数微调 90% 性能。